在对 RAG 有了简单认识之后,基于一些业务的场景,对 RAG 生态进行了一些探索。
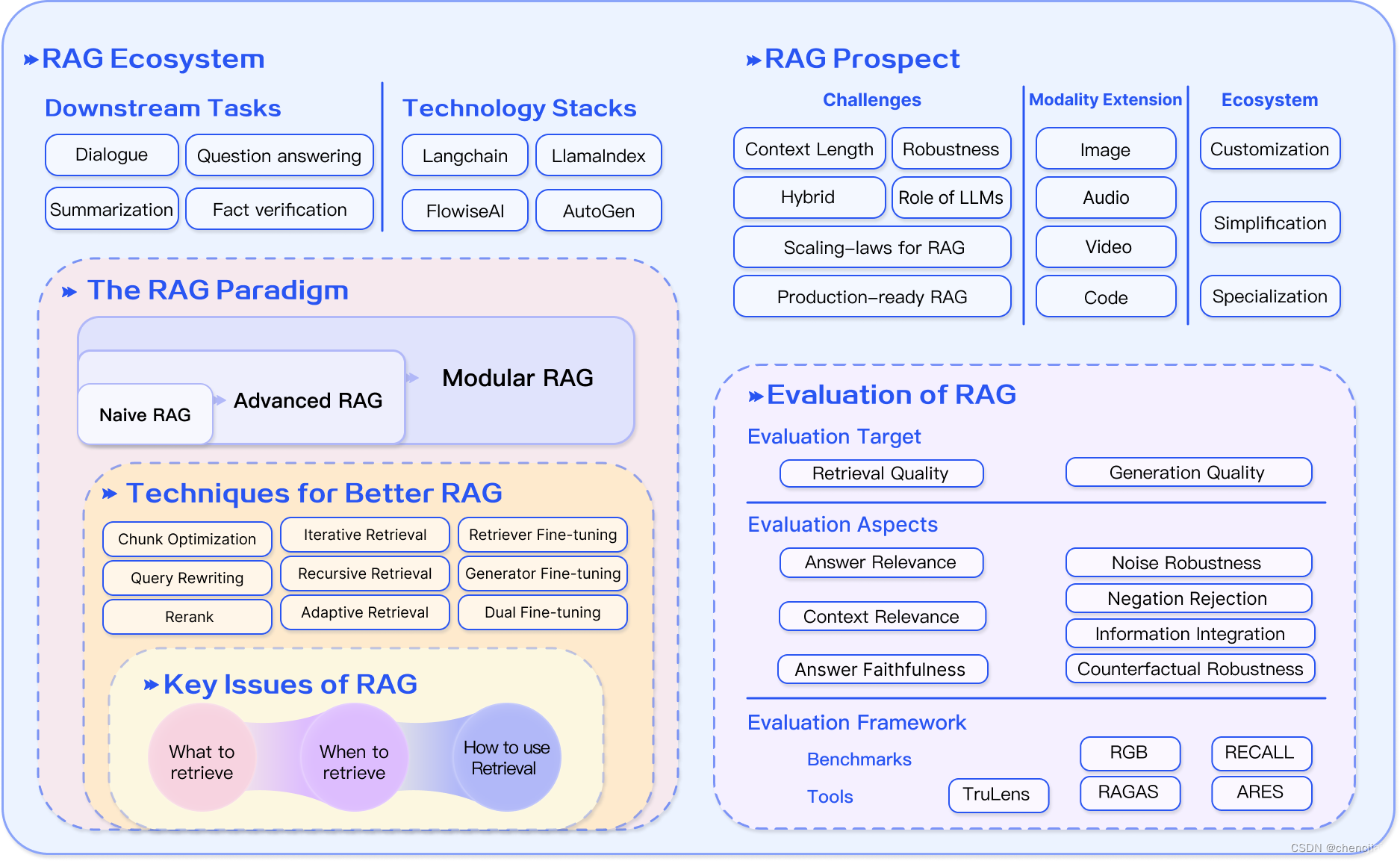
网上有一张 RAG 生态的概括图,我认为不错。
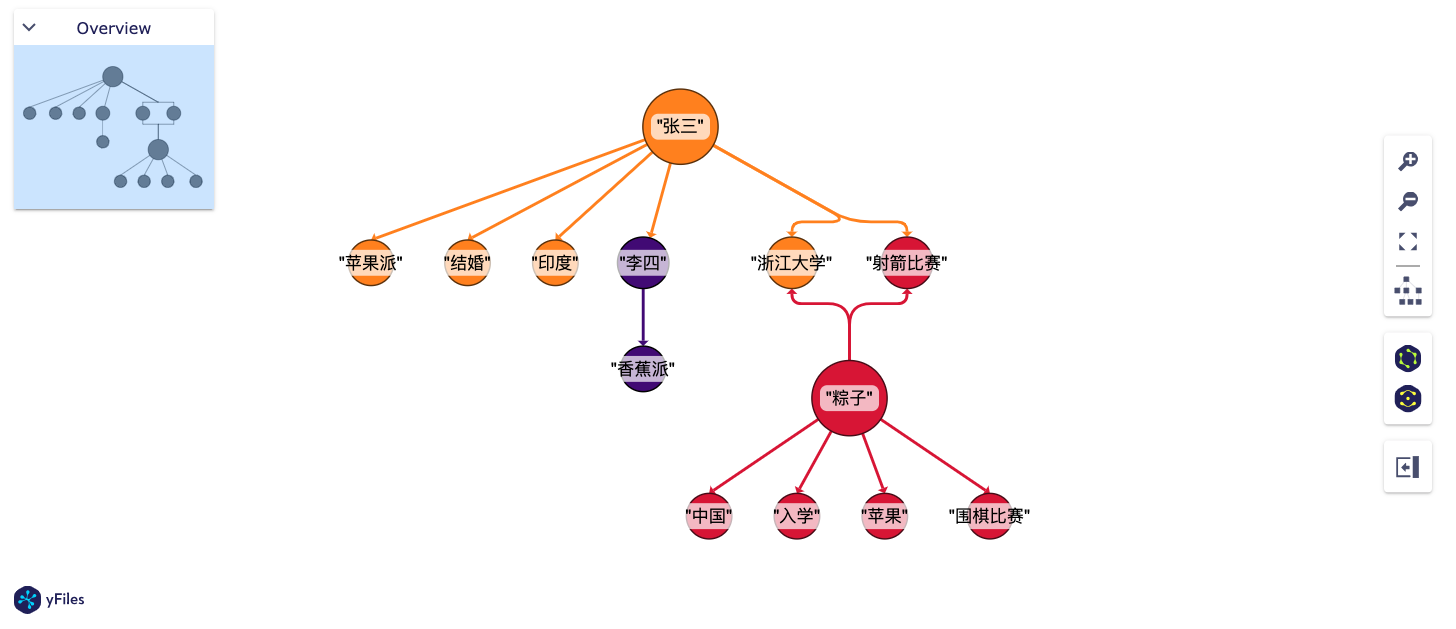
图谱
在 RAG 工作流中,考虑通过图谱的概念,生成更全面的一些信息以提升问答的功能。
尝试微软开源的 GraphRAG 对文本(大文本、多文本)提取实体、关系,以在问答环节可以尝试一些逻辑或者总结性的路由流程。
图谱相较于切片,具有更强的逻辑性,并且信息链更为清晰,而切片却有冗余以及无法多内容关联的问题。
当然了,也可以使用支持大 tokens 的 LLM 进行总结或其他动作,只不过这样会重复的消耗大 tokens ,从资源层面是浪费的。
以下是 GraphRAG 索引步骤:
⠋ GraphRAG Indexer
├── Loading Input (text)
├── create_base_text_units
├── create_base_extracted_entities
├── create_final_covariates
├── create_summarized_entities
├── join_text_units_to_covariate_ids
├── create_base_entity_graph
├── create_final_entities
├── create_final_nodes
├── create_final_communities
├── join_text_units_to_entity_ids
├── create_final_relationships
├── join_text_units_to_relationship_ids
├── create_final_community_reports
├── create_final_text_units
├── create_base_documents
└── create_final_documents
🚀 All workflows completed successfully.目前, GraphRAG 对不同类型的文档进行索引时,需要人为为工具提供实体类型(考虑是不是能由 LLM 代替),以在索引时能够更好的分析提取实体和其之间的关系。
所以如果需要接入到现有的 RAG 流程,需要 Python 编程调整各节点逻辑,以适配 RAG 流程。
视觉效果:
详细可查看
微调 Embeddings 模型尝试
使用 uniem 工具对模型进行微调,分别尝试过对 small 、 base 、 large 进行不同的微调对比,可能是数据集选用的关系,效果并不是特别理想,并且在大数据集的微调场景下,微调时间较长,成本较大,所以暂缓。
最后直接选用 bge-large-zh-v1.5 为本地 Embeddings 模型。
评测
使用 Ragas 工具进行 RAG 流程评测。在使用此工具前,采用人工测试集进行评测,并且评测维度较为主观。
需要注意 ⚠️ :在测试集生成和评测阶段,会大量消耗 LLM tokens ,请合理选择需要评测指标。
评测指标
| 指标名称 | 范围 | 含义 |
|---|---|---|
context_precision 上下文精度 |
(0,1) | 值越大,表示 ground_truth 与 contexts 越相关。 |
faithfulness 忠诚度/可信度 |
(0,1) | 由 answer 与 contexts 计算得出,值越大,表示 answer 更可信。 |
answer_relevancy 答案相关性 |
(-1,1) | 由 answer 、 contexts 与 question 计算得出,值越大,表示 answer 的相关性较好。 |
context_recall 上下文召回 |
(0,1) | 通过对 ground_truth 进行分解以验证是否可以归因于 contexts ,值越大,表示性能越好(避免反复尝试)。 |
context_entity_recall 上下文实体召回 |
(0,1) | 分别计算 ground_truth 和 contexts 的实体,使用其实体进行召回,值越大,表示性能越好(避免反复尝试)。 |
answer_similarity 答案语义相似度 |
(0,1) | 由 answer 与 ground_truth 计算得出,值越大,表示 answer 与 ground_truth 更相似。 |
answer_correctness 答案正确性 |
(0,1) | 由 answer 与 ground_truth 计算得出,值越大,表示 answer 与 ground_truth 一致性越高。 |
AspectCritique 方面批评 |
- | 用于评测 answer 的内容是否包含评测「方面」的内容,如有害性、恶意性、连贯性、正确性、简洁性 |
summarization_score 总结分数 |
- | - |
所以在不考虑 LLM tokens 的情况下,可以利用自动化评测工具来优化现在有的 RAG 应用,不限于 RAG 流程、Prompt 工程等,相较于人工测试集,可以说效率大大提升。
详细可查看
- 本文链接: https://zongzi531.github.io/2024/09/01/rag%E7%94%9F%E6%80%81%E6%8E%A2%E7%B4%A2/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!