初识 RAG
继上个月对 Sentence Transformers 框架下的 embedding 模型有了简单的尝试和使用后,现在对 RAG 有了简单的认识。
用一张图来解释最为合适不过了。
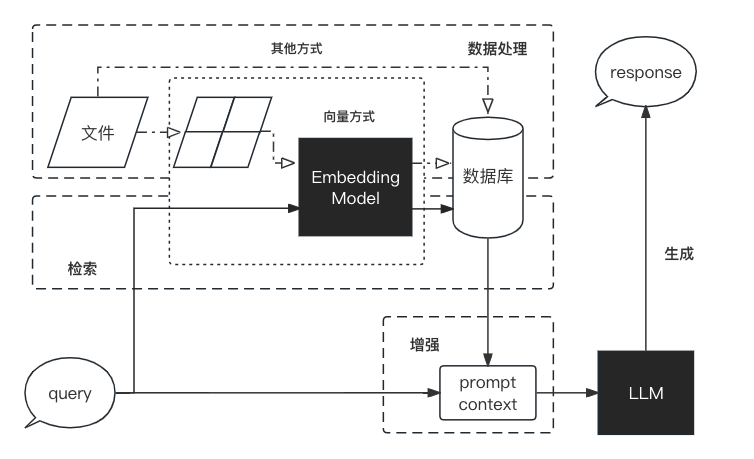
图片来自 llm-universe
关于什么是 RAG 这里就不多做介绍了,其实回顾下来,可以发现 RAG 的流程中,还有很多的优化点,可以更好的优化 LLM 在回答问题过程中的幻觉问题。
例如:
- 文件在解析过程中的清洗操作,包括不限于对不同类型的文件进行特殊处理,对图片视频音频等媒体资源进行识别转文字或向量化。
- 知识库场景下,对单文件整篇进行总结、多文件集合总结。
以上优化目的在于尽可能产生多的向量可能与 Query 进行匹配,丰富进入 LLM 时生成 prompt 的内容。
- Query 也可以在向量化前,经过 LLM 生成相似的 Query 生成多个向量进行查询匹配的优化逻辑。
- 知识库场景下,对存在的数据进行自动化知识图谱生成,并且优化 Query 的向量化流程,以能够更好的匹配到问题的领域,避免越界的同类词汇出现的问题。
- Query 的 Chat 场景对一些模糊内容可以提供一些交互式的引导,来辅助问答。
我们也在尝试着使用 RAG 来研发一个新型的知识库,解决传统知识库需要问题内容强匹配的问题,期望提供一个更易用的知识库。
其实 RAG 完全不限于知识库的场景。
在辅助编程领域,可以结合自身的代码合集进行更精准的推荐,也可以避免一些技术过时的问题,等等。
同样的,在办公领域,可以结合自身的业务领域,实现类似自动生成 Word 、 PPT 、PDF 等文件。
总之,可以让 LLM 的回答更实时、更准确、更专业。
回过来想一下, RAG 其实也会演变成一个基座,在此基座上衍生产品。
比较疑惑的点是,目前对 LLM 了解的并不充分,可以明白 LLM 对自然语言的理解还不错,但是对一些数理化的内容,似乎并不擅长,是不是在 LLM 的过程中引导进行推理可以提升准确率呢……
所以 RAG 之路,还很长……
- 本文链接: https://zongzi531.github.io/2024/08/01/%E5%88%9D%E8%AF%86rag/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 3.0 许可协议。转载请注明出处!